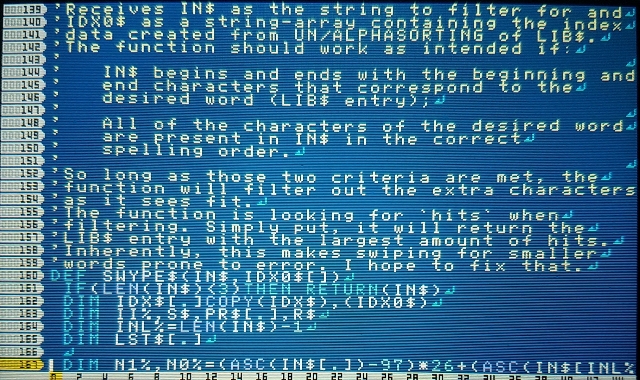
Swype Keyboard
Root / Submissions / [.]
Download:JRTE3KNV
 Version:Size:
Version:Size:
Swype has been updated to make amends for the problems it had the last runaround. The algorithm is now faster and can easily handle larger libraries (the library in this update has 10k words).
I've added comments throughout the code to make everything more understandable. You can easily port this over into your own programs, so long as you're careful with copying over all the functions and the global variables too. This also includes a custom keyboard function—which itself is fairly flexible—because the default keyboard will not work for this.
This may be the only update I give for this, unless I get some JN brainblast sort-o-thing to help me figure out how to introduce the touch-vector observation/analyzation necessary for higher right-return accuracy.

Replying to: Guzzler
Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Much slower you say? I think I can fix that.
Edit: is your 10k list SORTed?
Nice. I wonder if I can combine this with an SB IDE.
Shhhhh...
I may or may not already be developing that
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Alphabetically, yes.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Wait, I misunderstood. I honestly don't know what SORT does lol.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
That may be a factor. I can't see why it would be so slow, because in the initial phase of the algorithm, it trims down your list to a tiny fraction containing phrases with only the beginning and end characters. From 10,000, you'd only expect at most a hundred such entries (if consistency prevails). It really shouldn't be that bad. I'll give it a test with a 10k word dump later on.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
A sorted list of size 2,500 should only take 12 iterations to find any item in the list, and a sorted list of 10,000 should only take 14 iterations to find any item in the list. Increasing the size of the dictionary should not cause slow down in something like this.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Okay, so I took a decent shower and it quickly occurred to me that every time you call the Swype function, it runs through the entire library once in a FOR loop. This must be the issue, because running through a string array of 10,000 indexes is consuming.
I could remove that function and add another argument to the Swype function that calls for a kind of metadata which points to where each sub-alphabetical list of entries are. So basically, I wouldn't need to search your entire library to know where "t" starts, I could simply run through it once and store that information.
Hell, if I create a new sorting algorithm that best suits my needs, I'd really be in business, because the next slowest thing is pretty much the same thing as the last problem except it runs through all of the entries it initially pulled from the first run-through, looking for entries sharing the same end-character.
The sorting function would need to sort entries alphabetically only by the first and end characters, disregarding all characters in between.
Yes, such a function would really boost the speed ...
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
@amihart
Well, I am performing a check on each element in the array, and I am also pushing information from that check onto a new stack, so it's a little more than just running through the array.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
If your array is sorted and you're running through each element, you're doing something wrong. There's always a faster way if the data is sorted. Such as, if you are just doing a single lookup in a list of size 10k, it would take 14 iterations to find any element using a binary search (doing 10k iterations through the whole thing is overkill). Depending on what exactly your algorithm is doing (I haven't looked at it yet so I don't know exactly what you are doing), there will likely be some way you an utilize the fact it's sorted to help you isolate the information you need.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
You should at least only look through the entries that begin with the given initial letter.
Also, I wonder if it would be good to sort entries based on a system that acknowledges keyboard position, though I'm not sure how such a system would be designed. Maybe some kind of irregular constellation. Then it's easier to do the fuzzy matching.
Edit: ignore this, I forgot swype input won't look close to the intended string
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Actually, acknowledging keyboard position (namely, the positions of the keys) is not a bad idea. For most smaller words, say, "me," you have to trek across the keyboard hitting many keys, which may sometimes render as other words with (unintentionally) more algorithmic "hits" than the short, intended word.
By observing the direction of the Swype relative to the positions of the keys, it may help for determining when the user intends to type a shorter word versus a potential longer one.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
My understanding of the idea with length approximation is to track changes in stroke direction. A sharp change in direction is a high-probability intended key in the approximate area. The problem with this is obviously that there are words where intended letters lie between each other on the arrangement e.g. [w]->[e]->[t] = [w][t]. I'm pretty sure even mobile Swype still has trouble with midpoint key hits.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Perhaps it would be better/easier to track changes in SPEED. In the example "wet", the user might slow down around the E, and any direction change is also going to be a change in speed, too.
Replying to:Guzzler
Really neat. I made my own, longer list of words(10,000) and tried it. It was much slower. Anyway, neat concept.
Actually, in my testing phase, I found that to be incorrect. Speed remains relatively constant throughout the swipe (unless you deliberately slow yourself of course, perhaps as a learning user). Searching for changes in direction could add to the success rate of the algorithm. I imagine it would be implemented in a weighted system, where characters which occupied the swipe's change-of-direction would have more weight over other characters present in other potential results (some "turns" could be wider arcs which skew results, so, unlike the beginning and end characters which are given, you can't say for certain a turn lying on a character is definite).
Actually, I think this would be particularly useful for words contained entirely or partially within one key row, ex: "writer, quote, purpose, etc." because those words are the ones the algorithm has most trouble rendering correctly.
Replying to: SwanBot
SwanBot
I was saddened to see no iteration of the word "cake" in there.
Get me the word cake and I'll thumbs up.
My current working version (not yet updated) has cake and cakes.